Companies of all sizes across industries are struggling to effectively manage the vast amounts of data that are flowing in from hundreds and thousands of sources today.
One key aspect of this challenge is deciding where to store all this data to adopt powerful data analytics for insights.
There are a few options available: data warehouses, data lakes, and data lakehouses. Each of them has specific strengths and weaknesses, and understanding which is the right way to go is often a daunting task.
In this article, you will learn about the key differences between these storage solutions and how to make an optimum decision for your organization.
Data warehouse
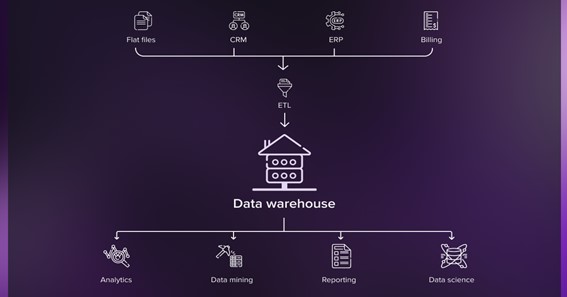
Data warehouses pull in structured and semi-structured data from systems that track transactions and day-to-day operations, including business apps, financial systems, or PoS and other sales tools. This data is organized using a predefined logical configuration to allow speedy access for business intelligence and report generation purposes.
Architecturally, data warehouses have a bottom layer for an Extract, Transform and Load (ETL) tool to ingest data, a middle layer for an online analytical processing (OLAP) server to enable fast queries, and a top layer for APIs to integrate data analytics systems. They also comprise data marts that provide relevant data subsets for different business units and operational data stores that house data from the company’s current operations for producing lightweight reports.
Companies have been successfully implementing data warehouses for years, often turning to providers of data warehouse consulting services to maximize the potential of their data assets.
Originally, these solutions were on-premises only. In recent years, there has been a trend toward moving them to the cloud, which offers cost effectiveness, scalability, and simple integration with any service a company may need. However, on-premises solutions continue to be a popular choice today because of their benefits, such as a lack of latency, total control and privacy over data, and a lower security risk.
A data warehouse has several major uses, including business performance assessment and reporting, one-off analysis performed to answer a stakeholder’s question, data mining, and dashboard-based data visualization.
Click here – Expected Cold Chain Sector Trends For Pharma In 2022 And 2023
Data lake
These repositories house raw data in its original form and allow for next-level analysis using real-time streams of data and ML algorithms. Unlike data warehouses, they also absorb media rich data and various documents in unique formats (i.e., unstructured data).
Data lakes provide an important springboard for digging into the company’s big data to identify trends, changes, and potential business opportunities.
Consuming enormous amounts of data, data lakes, however, can easily turn into a data swamp. To avoid this, it is critical to follow best governance practices and adopt robust data management.
The architecture of a data lake comprises separate layers for initial data storage, enhancement, annotation, and exploration. Data lakes are not equipped with built-in analytics capabilities, so organizations utilize additional tools to analyze the data stored in them, including data warehouses.
Today, data lakes are often hosted on cloud platforms that come with affordable object storage and data management solutions. Local data lakes that are deployed by companies on their own servers are also common due to security issues usually associated with cloud data storage.
Data lakes are built to support stream analytics, machine learning projects, advanced BI, and bespoke data analytics solutions.
Click here – How to fight a personal injury claim with the support of a lawyer
Data lakehouse
A data lakehouse is a hybrid system that combines the capabilities of the two storage solutions described above. As such, it enables organizations to manage data of any type in a central location, while also facilitating sophisticated analysis and supporting a wide range of workflows.
Data lakehouses are usually made up of a storage layer, a computing layer that provides capabilities similar to a data warehouse, APIs for integrating with data assets, and a serving layer for supporting different types of workloads.
The data lakehouse was first introduced in 2017 and has gained popularity in recent years, with several major technology companies offering solutions based on this concept.
This new storage solution aims to address the common problems with traditional data warehouses and data lakes, including a lack of big data analysis support and a significant scaling effort that comes with the former and poor data quality and integration complexities that are associated with the latter.
Today, data lakehouses are becoming an increasingly popular option for organizations looking to harness big data and AI technologies.
How to determine the best solution for your company
Selecting the most suitable data storage solution for your company can be difficult as technology is evolving and vendors are refining their offerings.
However, there are rules of thumb.
First of all, it is important to analyze use cases as the three storage solutions serve different business purposes. So consider the type of analysis you need to perform. For instance, a data warehouse is ideal for regular updates on the organization’s business performance and business intelligence purposes, while a data lake or a lakehouse is better suited for experimental and exploratory analysis. However, if your organization operates in a heavily regulated industry, you may need to prioritize compliance and choose a data warehouse.
Also, your decision can depend on the time and money you are ready to spend on your data storage. Data lakes can be faster and cheaper to build than data warehouses, as it is possible to start small to augment existing and build new capabilities step by step in an agile way.
Other key considerations can be the importance of data consistency and timeliness for your company and the expertise of your data team.
If you are still unsure about which storage solution to choose, you can always turn to an experienced provider of big data development services for valuable advice.